Linux Tuning linux network tuning
Clone From Here
##Linux Network Tuning
This page contains a quick reference guide for Linux 2.6+ tuning for Data Transfer hosts connected at speeds of 1Gbps or higher. Note that most of the tuning settings described here will actually decrease performance of hosts connected at rates of OC3 (155 Mbps) or less, such as home users on Cable/DSL connections.
Note that the settings on this page are not attempting to achieve full 10G with a single flow. These settings assume you are using tools that support parallel streams, or have multiple data transfers occurrin in parallel, and want to have fair sharing between the flows. As such the maximum values are 2 to 4 times less than what would be required to support a single stream. As an example, a 10Gbps flow across a 100ms network requires 120MB of buffering. Most data movement applications, such as GridFTP, would employ 2-8 streams to do this efficiently and to guard against congestive packet loss. Setting your 10Gbps capable host to consume a maximum of 32M - 64M per socket ensures that parallel streams work well, and do not consume a majority of system resources.
If you are trying to optimize for a single flow, see the tuning advice for test/measurement hosts page.
###Background Information
####TCP Buffer Sizing
TCP uses what is called the “congestion window”, or CWND, to determine how many packets can be sent at one time. The larger the congestion window size, the higher the throughput. The TCP “slow start” and “congestion avoidance” algorithms determine the size of the congestion window. The maximum congestion window is related to the amount of buffer space that the kernel allocates for each socket. For each socket, there is a default value for the buffer size, which can be changed by the program using a system library call just before opening the socket. There is also a kernel enforced maximum buffer size. The buffer size can be adjusted for both the send and receive ends of the socket.
To get maximal throughput it is critical to use optimal TCP send and receive socket buffer sizes for the link you are using. If the buffers are too small, the TCP congestion window will never fully open up. If the receiver buffers are too large, TCP flow control breaks and the sender can overrun the receiver, which will cause the TCP window to shut down. This is likely to happen if the sending host is faster than the receiving host. Overly large windows on the sending side is not usually a problem as long as you have excess memory; note that every TCP socket has the potential to request this amount of memory even for short connections, making it easy to exhaust system resources.
The optimal buffer size is twice the bandwidth*delay product of the link:
buffer size = 2 * bandwidth * delay
The ping program can be used to get the delay. Determining the end-to-end capacity (the bandwidth of the slowest hop in your path) is trickier, and may require you to ask around to find out the capacity of various networks in the path. Since ping gives the round trip time (RTT), this formula can be used instead of the previous one:
buffer size = bandwidth * RTT
For example, if your ping time is 50 ms, and the end-to-end network consists of all 1G or 10G Ethernet, the TCP buffers should be:
.05 sec * (1 Gbit / 8 bits) = 6.25 MBytes.
Historically in order get full bandwidth required the the user to specify the buffer size for the network path being used, and the the application programmer had to set use the SO_SNDBUF and SO_RCVBUF options of the BSD setsockopt() call to set the buffer size for the sender an receiver. Luckily Linux, FreeBSD, Windows, and Mac OSX all now support TCP autotuning, so you no longer need to worry about setting the default buffer sizes.
More details on TCP buffer sizing can be found in my LAMP article and in the PSC TCP Tuning Guide.
####TCP Autotuning
Beginning with Linux 2.6, Mac OSX 10.5, Windows Vista, and FreeBSD 7.0, both sender and receiver autotuning became available, eliminating the need to set the TCP send and receive buffers by hand for each path. However the maximum buffer sizes are still too small for many high-speed network path, and must be increased as described on the pages for each operating system.
####TCP Autotuning Maximum
Adjusting the default maximum Linux TCP buffer sizes allows the autotuning algorithms the ability to scale the sending and receiving window to take advantage of available bandwidth on long paths. Each operating system reacts to this setting differently, please see operating system specific resources on recommendations.
The following graph illustrates the impact of adjusting this value on two Linux servers that are separated by a 75ms round trip path. The value was adjusted from 32MB to 64MB, and resulted in a throughput improvement of nearly 2 times.
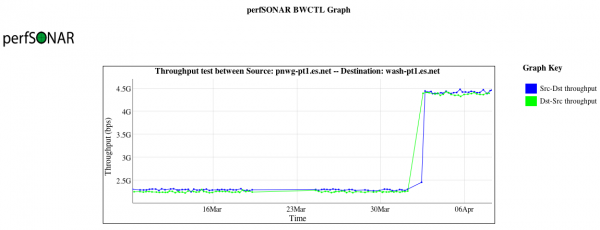
ESnet recommends sensible defaults for this value, of between 32M and 128M. An expectation of 10Gbps, single stream, across a path of 100ms, will require a 120MB buffer, baring any network loss. Hosts that have an expectation of faster speeds or longer distanes will need more. Those intending to use parallel streams should use less to avoid memory exhaustion.
###General Approach
To check what setting your system is using, use ‘sysctl name’ (e.g.: ‘sysctl net.ipv4.tcp_rmem’). To change a setting use ‘sysctl -w’. To make the setting permanent add the setting to the file ‘sysctl.conf’.
The following are important for TCP performance, and the default values of 1 are fine:
[net.ipv4.tcp_window_scaling](http://en.wikipedia.org/wiki/TCP_window_scale_option)
[net.ipv4.tcp_timestamps](http://freesoft.org/CIE/RFC/1323/7.htm)
[net.ipv4.tcp_sack](http://www.opalsoft.net/qos/TCP-90.htm)
Notes:
some people recommend disabling tcp_timestamps.as doing that reduces CPU
load. We do not recommend this for high-speed networks. It may help for home
users on slow networks, as timestamps add an additional 10 bytes to each
packet. But more accurate timestamp make TCP congestion control algorithms
work better, so we strongly disagree with that recommendation for WAN
performance, as we have observed that the default value of 1 helps in more
cases than it hurts, and can help a lot.
some people recommend increasing net.tcp_mem. This is not usually needed.
tcp_mem values are measured in memory pages, not bytes. The size of each
memory page differs depending on hardware and configuration options in the
kernel, but on standard i386 computers, this is 4 kilobyte or 4096 bytes. So
the defaults values are fine for most cases.
###TCP tuning
Like most modern OSes, Linux now does a good job of auto-tuning the TCP buffers, but the default maximum Linux TCP buffer sizes are still too small. Here are some example sysctl.conf commands for different types of hosts.
For a host with a 10G NIC, optimized for network paths up to 100ms RTT(get by ping), and for friendlyness to single and parallel stream tools, add this to /etc/sysctl.conf
# allow testing with buffers up to 64MB
net.core.rmem_max = 67108864
net.core.wmem_max = 67108864
# increase Linux autotuning TCP buffer limit to 32MB
net.ipv4.tcp_rmem = 4096 87380 33554432
net.ipv4.tcp_wmem = 4096 65536 33554432
# increase the length of the processor input queue
net.core.netdev_max_backlog = 30000
# recommended default congestion control is htcp
net.ipv4.tcp_congestion_control=htcp
# recommended for hosts with jumbo frames enabled
net.ipv4.tcp_mtu_probing=1
For a host with a 10G NIC optimized for network paths up to 200ms RTT, and for friendlyness to single and parallel stream tools, or a 40G NIC up on paths up to 50ms RTT:
# allow testing with buffers up to 128MB
net.core.rmem_max = 134217728
net.core.wmem_max = 134217728
# increase Linux autotuning TCP buffer limit to 64MB
net.ipv4.tcp_rmem = 4096 87380 67108864
net.ipv4.tcp_wmem = 4096 65536 67108864
# increase the length of the processor input queue
net.core.netdev_max_backlog = 250000
# recommended default congestion control is htcp
net.ipv4.tcp_congestion_control=htcp
# recommended for hosts with jumbo frames enabled
net.ipv4.tcp_mtu_probing=1
Notes:
A number of performance experts say to also increase `net.core.optmem_max`
to match `net.core.rmem_max` and `net.core.wmem_max`, but we have not found
that makes any difference.
Starting in Linux 2.6.7 (and back-ported to 2.4.27), Linux includes alternative congestion control algorithms beside the traditional ‘reno’ algorithm. These are designed to recover quickly from packet loss on high-speed WANs. Starting with version 2.6.13, Linux supports pluggable congestion control algorithms. The congestion control algorithm used is set using the sysctl variable net.ipv4.tcp_congestion_control, which is set to bic/cubic or reno by default, depending on which version of the 2.6 kernel you are using.
To get a list of congestion control algorithms that are available in your kernel (kernal 2.6.20+), run:
sysctl net.ipv4.tcp_available_congestion_control
The choice of congestion control options is selected when you build the kernel. The following are some of the options are available in the 2.6.23 kernel:
reno: Traditional TCP used by almost all other OSes. (default)
cubic: CUBIC-TCP
bic: BIC-TCP
htcp: Hamilton TCP
vegas: TCP Vegas
westwood: optimized for lossy networks
If cubic and/or htcp are not listed when you do ‘sysctl net.ipv4.tcp_available_congestion_control’, try the following, as most distributions include them as loadable kernel modules:
/sbin/modprobe tcp_htcp
/sbin/modprobe tcp_cubic
NOTE:There seems to be bugs in both bic and cubic for a number of versions of the Linux kernel up to version 2.6.33. (the 2.6.18 kernel used by Redhat Enterprise Linux 5.3 - 5.5 and its variants. Centos, Scientific Linux, etc.) We recommend using htcp with a 2.6.18.x kernel to be safe.
For long fast paths, we highly recommend using cubic or htcp. Cubic is the default for a number of Linux distributions, but if is not the default on your system, you can do the following:
sysctl -w net.ipv4.tcp_congestion_control=htcp
On systems supporting RPMS, You can also try using the ktune RPM, which sets many of these as well.
If you are using Jumbo Frames, we recommend setting tcp_mtu_probing = 1 to help avoid the problem of MTU black holes. Setting it to 2 sometimes causes performance problems.
More information on tuning parameters and defaults for Linux 2.6 are available in the file ip-sysctl.txt, which is part of the 2.6 source distribution.
Warning on Large MTUs: If you have configured your Linux host to use 9K MTUs, but the connection is using 1500 byte packets, then you actually need 9/1.5 = 6 times more buffer space in order to fill the pipe. In fact some device drivers only allocate memory in power of two sizes, so you may even need 16/1.5 = 11 times more buffer space!
And finally a warning: for very large BDP paths where the TCP window is > 20 MB, you may hit the Linux SACK implementation problem. If Linux has too many packets in flight when it gets a SACK event, it takes too long to locate the SACKed packet, and you get a TCP timeout and CWND goes back to 1 packet. Restricting the TCP buffer size to about 12 MB seems to avoid this problem, but clearly limits your total throughput. Another solution is to disable SACK. This appears to have been fixed in version 2.6.26.
Also, I’ve been told that for some network paths, using the Linux ‘tc’ (traffic control) system to pace traffic out of the host can help improve total throughput.
###UDP Tuning
####NIC Tuning
This can be added to /etc/rc.local to be run at boot time:
# increase txqueuelen for 10G NICS
/sbin/ifconfig ethN txqueuelen 10000
Note that this might have adverse affects for a 10G host sending to a 1G host or slower.
We also note that we have seen about a 30% performance hit using VLANS with Linux with some hosts/NICS, as it can break the hardware offload capabilities. Myricom mentions this here.
For more information on TCP variables
###VM Network Tuning
To get the best network performance on a Linux VM running on a native Linux host, increase txqueuelen in host OS, and set all other tuning parameters in the guest OS.
###Reference
###Suffix
RWND: Receiver Window BDP : Bandwidth Delay Product WSCAL: EThe window scale option